| Re: [eigen] Block CG(p=1) vs CG Classic |
[ Thread Index | Date Index | More lists.tuxfamily.org/eigen Archives ]
On 22.07.2013 21:40, Pedro Torres wrote:How much slower is it?
I'm new here and I have a newbie question. I have implemented a version of
Block Conjugate Gradient, to resolve AX=B where A(nxn), X(nxp) and B(nxp)..
Then, I compare the walltime of this block version (using p=1) agains
Classics CG using just VectorXd. Result: the block version took more time.
In general, products of MatrixXd(n,n) with VectorXd(n) are faster than with MatrixXd(n,1). Basically, the problem is that for Matrix*Matrix Eigen can make the same assumptions on alignment of each column.
Specifically I see that the operation A*V, with V defined as MatrixXd
V(n,1) took more time than the operations A*v, with v defined as VectorXd
v(n). Is this an expected result?. Can I do something to get approximately
more closer results?.
If you know your p at compile time you can make X and B
Matrix<double, Dynamic, p> which for p==1 is equivalent to VectorXd.
If your matrix A is generic dense, I would generally doubt that CG is the optimal method. If A is sparse, there might be some potential on Eigen's side to optimize Sparse*MatrixXd(n,p).
Sorry, can't see any attachment.
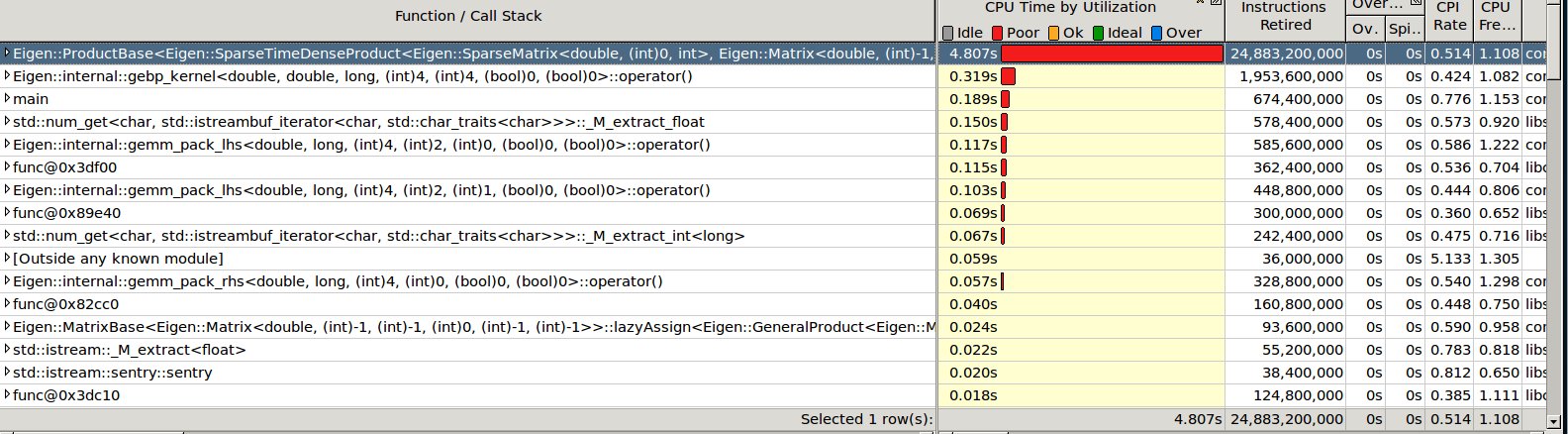
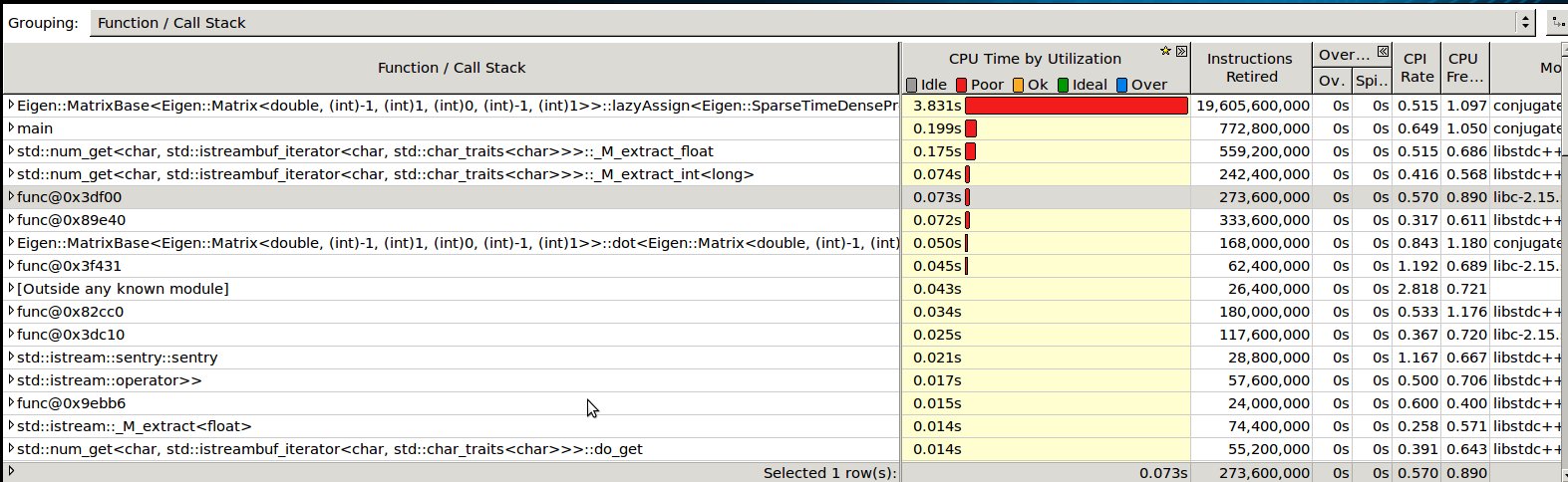
I attached some snapshot from VTune comparing this runs.
Christoph
--
----------------------------------------------
Dipl.-Inf., Dipl.-Math. Christoph Hertzberg
Cartesium 0.049
Universität Bremen
Enrique-Schmidt-Straße 5
28359 Bremen
Tel: +49 (421) 218-64252
----------------------------------------------
Attachment:
BCG.jpg
Description: JPEG image
Attachment:
cgclassic.jpg
Description: JPEG image
| Mail converted by MHonArc 2.6.19+ | http://listengine.tuxfamily.org/ |
{kind=link}
{kind=link}