| Re: [eigen] Specialized QR |
[ Thread Index | Date Index | More lists.tuxfamily.org/eigen Archives ]
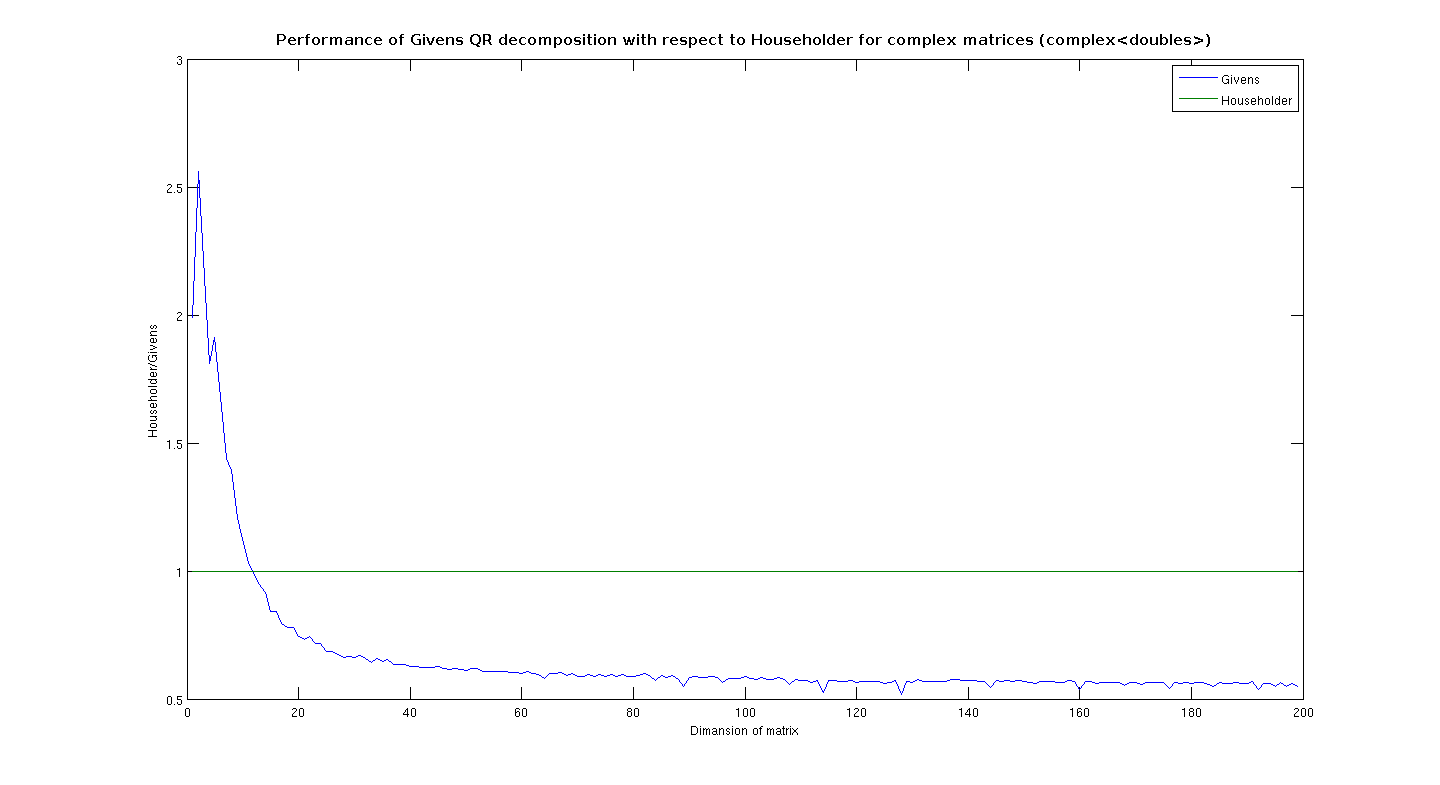
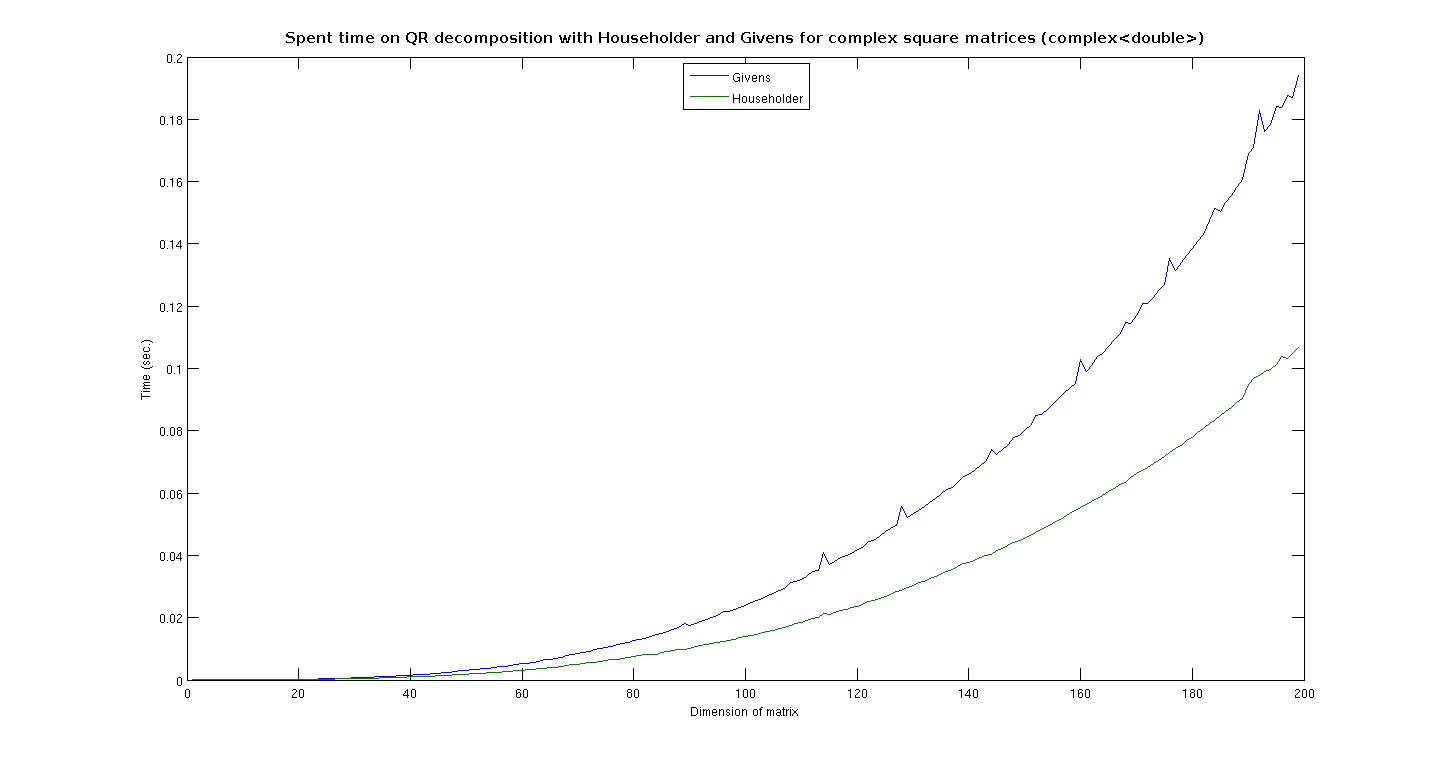
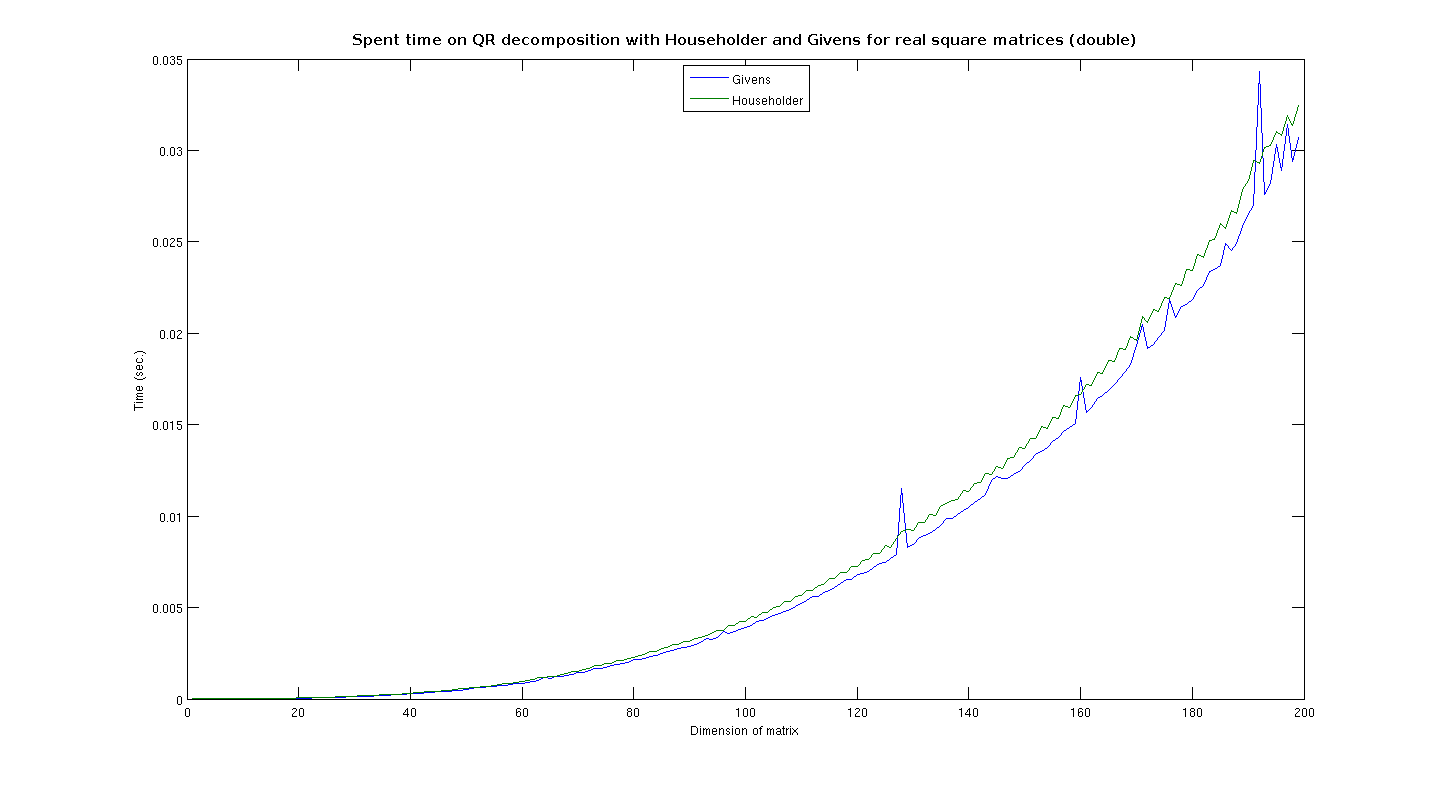
| I did a mistake with my benchmark. My class isn't 4 times faster as the QR class! In facts, the performance of the two classes was almost the same. I used only dynamically-sized matriced, but in theory thereis no difference between dynamic and fixed (the function is exactly the same). I made four graphics, which explain where QR_Givens is faster than QR. I noticed that for almost square matrices Givens is faster, but for MxN matrices, where M>2*N, Householder is far better. For complex ones, Givens is only faster with sizes up to 10x10; then it becomes far slower. In facts this topic isn't very well-named. I wrote a new class, I didn't any specialization. The benchmark shows that Givens is actually faster for small-sized (and real) matrices, but in the general case Householder is better. I think that we should try with Gram-Schmidt for small-sized matrices with many rows. I think that this behaviour is more general. Do you agree? Andrea Arteaga |
Attachment:
PerformanceComplex.png
Description: PNG image
Attachment:
PerformanceReal.png
Description: PNG image
Attachment:
TimeComplex.png
Description: PNG image
Attachment:
TimeReal.png
Description: PNG image
// This file is part of Eigen, a lightweight C++ template library
// for linear algebra.
//
// Copyright (C) 2009 Andrea Arteaga <yo.eres@xxxxxxxxx>
//
// Eigen is free software; you can redistribute it and/or
// modify it under the terms of the GNU Lesser General Public
// License as published by the Free Software Foundation; either
// version 3 of the License, or (at your option) any later version.
//
// Alternatively, you can redistribute it and/or
// modify it under the terms of the GNU General Public License as
// published by the Free Software Foundation; either version 2 of
// the License, or (at your option) any later version.
//
// Eigen is distributed in the hope that it will be useful, but WITHOUT ANY
// WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
// FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License or the
// GNU General Public License for more details.
//
// You should have received a copy of the GNU Lesser General Public
// License and a copy of the GNU General Public License along with
// Eigen. If not, see <http://www.gnu.org/licenses/>.
#ifndef QR_GIVENS_H
#define QR_GIVENS_H
/**
* QR_Givens
*
* QR decomposition of a matrix
*
* MatrixType is the type of the matrix of which we are computing the QR decomposition
*
* This class performs a QR decomposition using Givens rotations.
*/
template<class MatrixType>
class QR_Givens
{
public:
typedef typename MatrixType::Scalar Scalar;
typedef typename NumTraits<Scalar>::Real RealScalar;
enum {
Rows = MatrixType::RowsAtCompileTime,
Cols = MatrixType::ColsAtCompileTime,
isDynamic = (MatrixType::RowsAtCompileTime == Dynamic) ? 1 : 0,
isComplex = NumTraits<Scalar>::IsComplex,
q_Cols = Cols < Rows ? Cols : Rows-1,
m_Cols = Cols < Rows ? (Cols*Rows - Cols*(Cols+1)/2) : (Rows*(Rows-1)/2)
};
typedef Matrix<Scalar, Rows, Rows> MatrixQType;
typedef Matrix<Scalar, Rows, Cols> MatrixRType;
QR_Givens(const MatrixType& matrix) {
m_R = matrix;
compute_();
}
/** Returns the upper triangular matrix.
*
* Dimensions are the same as the matrix of which *this is the QR decomposition.
*/
MatrixRType matrixR() const;
/** Returns the orthogonal matrix.
*
* This is a quadratic matrix with the same number of rows as the matrix of which *this
* is the QR decomposition.
*/
MatrixQType matrixQ() const;
/** Returns the rank of the matrix of which *this is the QR decomposition.
*
* This method is not stable yet.
*/
int rank() const;
private:
inline void compute_();
Matrix<Scalar, Rows, Cols> m_R;
MatrixQType m_Q;
};
template<class MatrixType>
inline void QR_Givens<MatrixType>::compute_()
{
Scalar a, b, o1, o2, tmp;
RealScalar r;
const int rows = m_R.rows(), cols = m_R.cols();
const int q_cols = cols < rows ? cols : rows-1;
m_Q.resize(rows, rows);
m_Q.setIdentity();
for(int k1 = 0; k1 < q_cols; ++k1) {
for (int k2 = rows - 1; k2 > k1; --k2) {
b = m_R.coeff(k2, k1);
a = m_R.coeff(k1, k1);
r = ei_sqrt(ei_real(ei_conj(a)*a + ei_conj(b)*b));
o1 = a/r; // FIXME:
o2 = b/r; // what if r == 0 <=> (a==0 && b==0) ?
for (int i = k1; i < cols; ++i){
tmp = m_R.coeff(k1, i);
m_R.coeffRef(k1, i) = ei_conj(o1)*m_R.coeff(k1, i) + ei_conj(o2)*m_R.coeff(k2, i);
m_R.coeffRef(k2, i) = o1*m_R.coeff(k2, i) - o2*tmp;
}
for (int i = 0; i < rows; ++i){
tmp = m_Q.coeff(i, k1);
m_Q.coeffRef(i, k1) = o1*m_Q.coeff(i, k1) + o2*m_Q.coeff(i, k2);
m_Q.coeffRef(i, k2) = ei_conj(o1)*m_Q.coeff(i, k2) - ei_conj(o2)*tmp;
}
}
}
}
template<class MatrixType>
typename QR_Givens<MatrixType>::MatrixRType
QR_Givens<MatrixType>::matrixR() const
{
return Part<MatrixRType, UpperTriangular>(m_R);
}
template<class MatrixType>
typename QR_Givens<MatrixType>::MatrixQType
QR_Givens<MatrixType>::matrixQ() const
{
return m_Q;
}
#endif // QR_GIVENS_H
| Mail converted by MHonArc 2.6.19+ | http://listengine.tuxfamily.org/ |
{kind=link}
{kind=link}
{kind=link}
{kind=link}